git rebase -i HEAD~25

You can watch the video below, or keep reading for a transcript.

Git is complicated.

There are concepts known as threshold concepts or threshold knowledge, where once you cross a certain level of understanding it completely changes your perception of that concept.

My goal today is to push some of you a bit closer to the threshold edge to help make git a little less complicated.

Warning, I take no responsibility for any loss or damage you might suffer on your journey to git enlightenment.

In a perfect world, we solve problems perfectly. In my imperfect world, I might find and fix a bug mid feature. I might take a break from the feature and clean up the code. I might forget to pull in other peoples changes for a while. I might think I pulled in peoples changes, but haven't. I might chase down a rabbit, trying a bunch of things with a bunch of poorly formed, poorly named, and just plain awful commits. I might need to share code with a colleague that is riddled with half implemented work.
Reality is messy, and there is nothing wrong with changing our git commit history to tell a more compelling story about our intention with the changes, not the unfocussed journey that got us there.

Git rebase, and similar commands do allow us to change what actually happened. Purest might complain your repository is an untrue reflection of what truly happened. And, I agree! It's a good thing that git allows us to clean up our disorganized self and our disorganized code.
We alter history all the time. My first draft of this talk is very different that what I am presenting now. All other mediums are highly edited and tailored to the intended audience to deliver a clear and concise message, removing our mis-steps and better communicating our intent. This benefits the audience, which will be your colleagues and most likely also your future self.
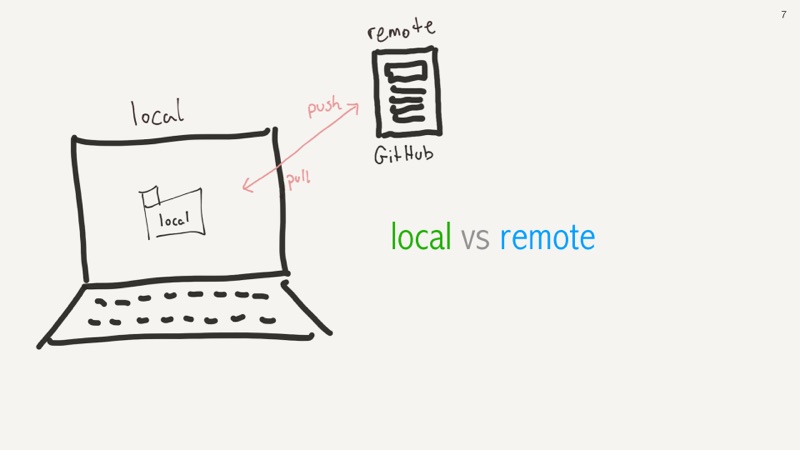
Git is a a distributed source code repository. Unlike centralized repositories such as Subversion, every copy of a git repo IS itself also a git repository, and every copy can behave like a server and most copies can also behave like a client. So you push to the remote server and you pull into your local client. Most people use it like a centralized repository, but it's not, so let's consider two falsehoods in what I just told you.
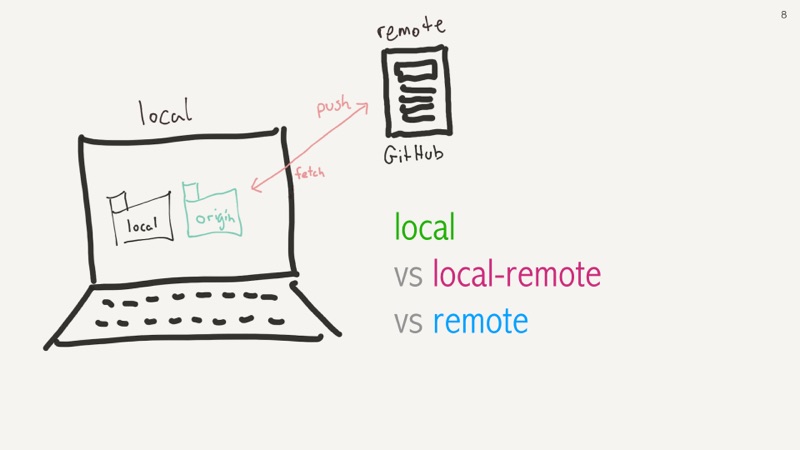
Firstly, you don't really pull into your local code. You actually fetch code from a remote repository and then you merge it into your local code. You now have your code locally, but also a local copy of the remote code. And then the legitimate remote code on the origin server.

If you look at your .git/config you will see the origin label is a variable,
not a constants, and these variables help hook up your local copy with a remote one.

Words matter. Master is an unfortunately named term in our industry and is the default name for your primary branch, in this talk I will refer to it as main. You might not always be able to change the default, but try, there are many better words without the emotional and historical baggage.
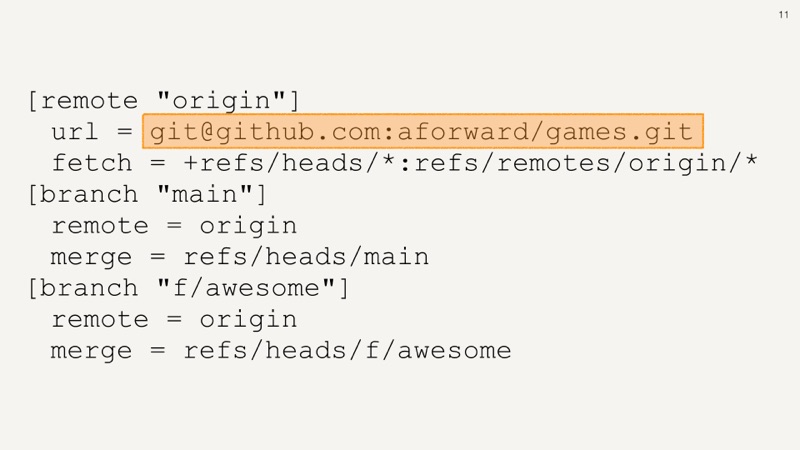
And origin refers to a remote git server to an imaginary repository on GitHub.

In this repo, we are tracking two remote branches main and f/awesome
that both refer back to our origin remote server.
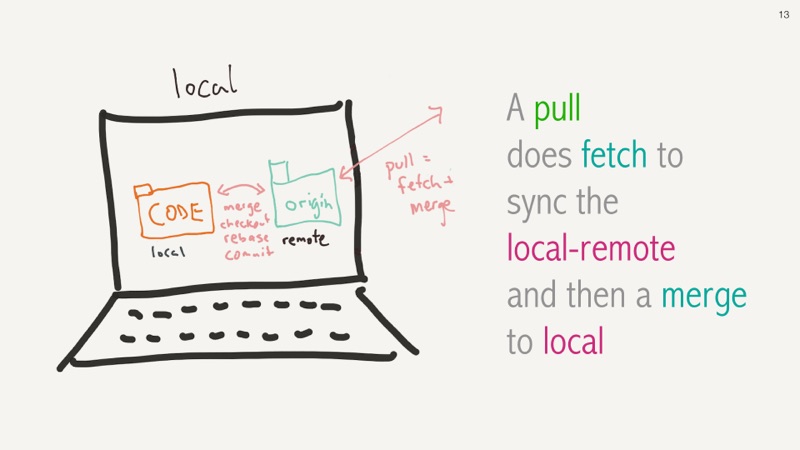
So git pull, which we might be used to using, actually updates your local
copy of the origin remote code using a git fetch, and then merges that
local origin code into our actual local local code.
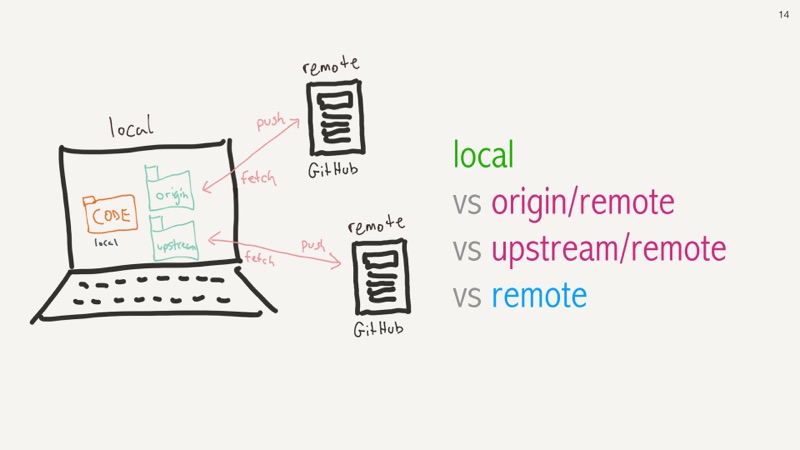
The second falsehood is about git's decentralization.
We mostly just push and fetch from the server, but we could have more,
so we are pedantically fetching from a server, and so each remote server
needs a uniquely identifying name. The default is origin but another
popular name is upstream.
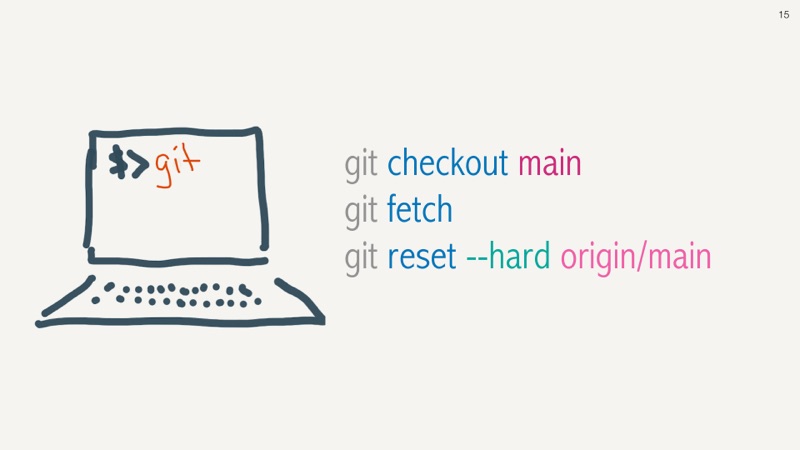
Let's now consider Amy, a developer getting back from a totally unplugged holiday.
First thing back, she wants to forcibly get the latest code from origin.
She enters the main branch, fetches code from the origin server and then does a
hard reset against the local origin/main branch.

This might be overkill, but Amy know she has no local changes and wants to start fresh. Other reasons to do a hard reset could be that you are lost in the git-universe and need to reset yourself to a known place.

Amy is now to ready to work on a new “jump to conclusions” feature. She creates a new branch,
and then immediately tells the origin server about this new branch so that she can push and fetch with ease.

Git checkout serves many purposes, and very recently, as of last August,
git is providing two separate commands
to track those purposes with better names. We can now git switch to jump between branches and git restore
to undo local changes. I will continue to use git checkout for this talk, just know that change is coming.

Amy makes great progress on the feature, trying to follow the mantra of make the hard change easy, and then make the easy change... one small commit at a time.

Amy was in a rush on that last commit “doing stuff” and could write a better message. She amend's that last commit changing the message to “hard change”.

And now we have diverged. Even changing the description of a commit changes the commit.
So now our local feature branch is different from our local copy of our origin remote branch.
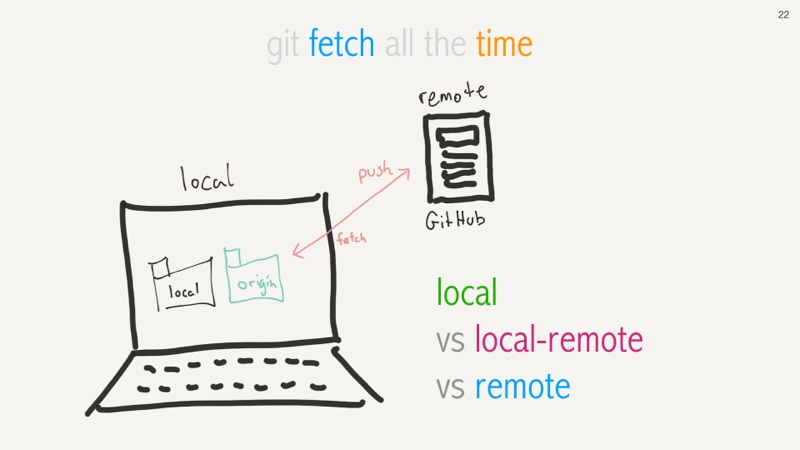
Git status is not a network operation. So we could still be behind our remote version of the
remote code. That's why we want to git fetch all the time. This will reduce accidental
conflicts when you thought you had the latest remote code, but actually didn't.
This diverged makes sense because we changed our commit, we changed history.
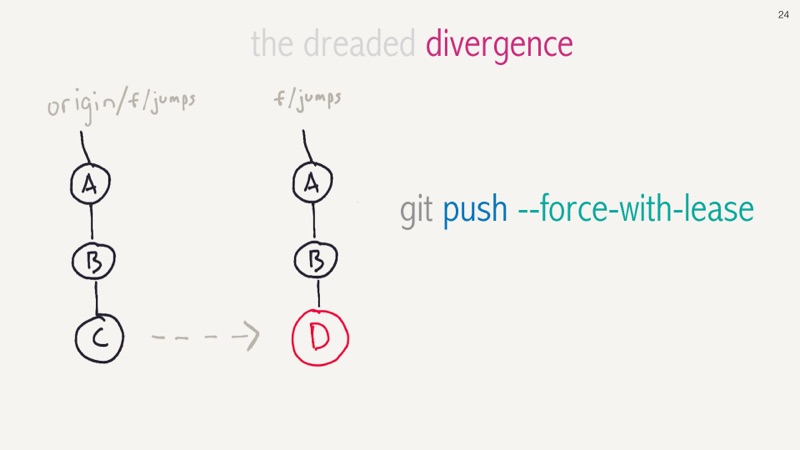
Visually, we amended our last commit changing a “C” into a “D”. We did the change,
it's our branch, let's forcibly but with room for error push that to our remote
origin server using git push --force-with-lease. The “--with-lease” avoids overwriting
commits that others might have pushed to our branch.
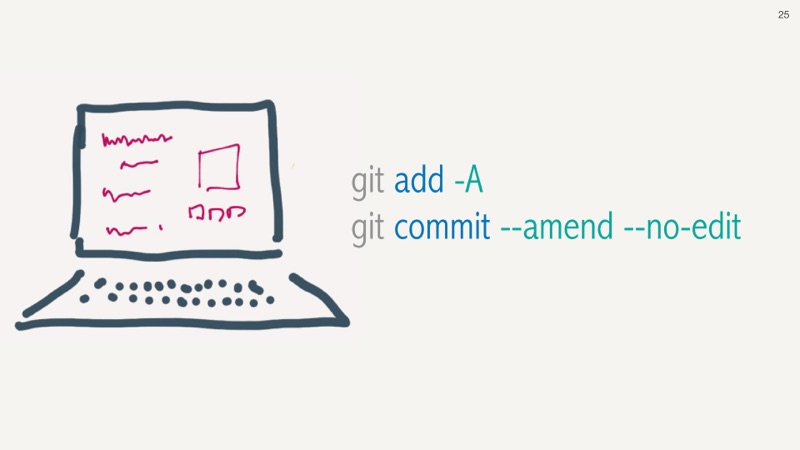
Amy then notices she also forgot to add a file to that last commit. Let's use the -A to add all
changes to avoid this going forward. We can also add a --no-edit flag as we don't want to change
the commit message this time.

But, the code isn't really flowing and does not tell a good story of “making the hard change easy, and then making the easy change”,
so Amy wants to re-order the commits to tell a better story of the progression of this feature. We can do this with an
interactive -i rebase.

Once the commits are in a better logical order, as opposed to their original dis-organized time-based order we are ready to push our diverged local branch. Again, this is our branch, we own it, we are the only ones working on it, so we are going to force our changes back to the origin server.

Amy leaves for the day, and back tomorrow to finish the work. Her teammate Bob was also
working and he pushed new code to the teams main branch. Let's pull that work into our branch.
First we need to fetch from our origin server. Second, we rebase against that local main branch
identified as origin/main. This origin/main is the local copy of the main branch stored in our remote server labelled origin.
Just like origin/f/jumps is the local copy of the f/jumps branch stored in our remote server labelled origin.

Visually. Yesterday Amy did some work in her local branch, but Bob was working too.

So today Bobs new commits are in the main branch, and are visible once we “git fetch”. Now we can rebase our work against that the new code. Amy and Bob communicate well together so no conflicts are expected.
The first step in a rebase will detach Amy's local commits from her branch.
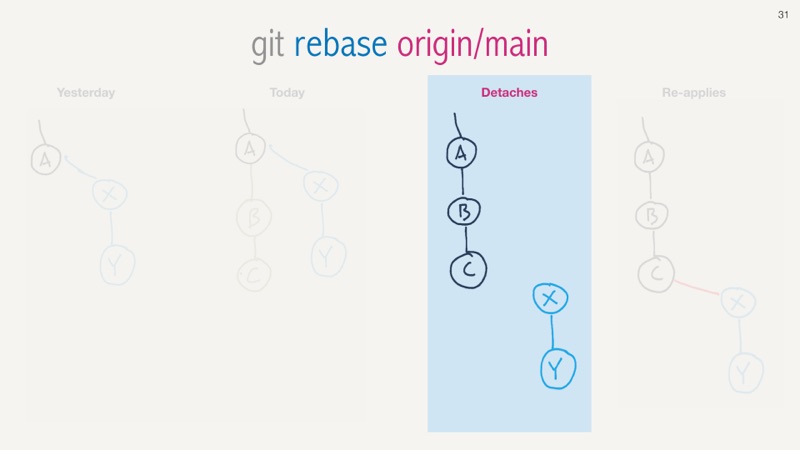
The first step in a rebase will detach Amy's local commits from her branch.

And then will re-attach it back to now include those changes from Bob.

The output tries to relay that information. We rewind back to where things diverged and then apply our changes in sequence to the new code base with the new commits.

With interactive rebase, you can also edit individual commits. The process is similar to debug breakpoints. Where the “applying of commits” will stop mid process and allow you to make changes. This is a great way to make fix up local errors in your local branch. Here you will edit that interim version of the code and make it more perfect. Add your changes and then continue on with the rebase.

And this is why rebase gets a bad name, and why we shouldn't rebase against shared branches like main. On the left was our tiny little amended commit. But, we forgot to push the change and then someone else (maybe even us) pushed code to that remote branch that still had the older “C” commit.
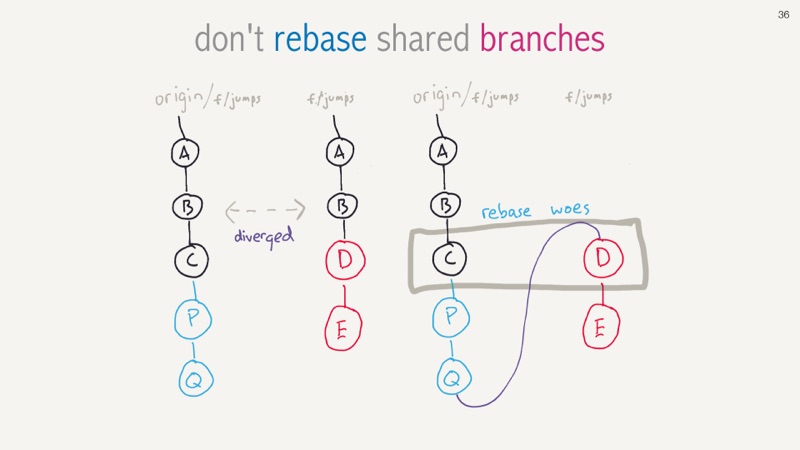
We have diverged at commit “B” and if try and rebase then things will go very badly, as we now have the older conflicting commit “C”, changes from others, and then our updated “D” commit and then our changes after that. The moral is really, please always be fetching, always push to your remote branch, and avoid changing history on shared branches.

If ever you are mid rebase and your repository catches fire with strange merge conflicts, warnings of empty commits, or if you messed up; then you can always give up with —abort flag and try again later if you dare. I sometimes get too over eager with changing history and —abort helps, a lot.

Back and Amy. She find's a bug in some of Bobs code, but he is not available so Amy goes ahead and fixes the issue locally.

As it is unrelated to Amy's feature work, she is in the habit of automatically moving those unrelated change to the top of her local commit history.

Amy likes to have unrelated bug fixes at the top of her commits, for just such an occasion.
Turns out the bug is affecting a lot of people and the change needs to be out today.
Amy's feature however isn't done, but because she isolated the bug fix and put it “next in line”
in her commit history we can safely cherry-pick it out of her branch, drop it into a a new
b/off-by-one branch and merge it separately without having to prematurely push her
unfinished feature.

When Amy returns to her feature branch, she can remove that commit by deleting it from her interactive rebase shell.

And then rebase against origin/main that now has that bug fix in its commit history.

Your git commit history should tell a story as the code evolved to deliver a great feature, fix an awesome bug and clean up the code. The reality might have been 8 mis-steps in 8 separate commits, some fat fingered typos, interspersed code clean up and random bug fixes.
Taking the poorly constructed story and editing it into a clear and concise summary of what you intended will help your future self when you return to this code in a few weeks, months or years.
Let's qualify this with an example.

We recently introduced Apple Pay at our company. Here's an isolated snippet of code to create an Apple Pay Session to get the payment process going.

The Apple Pay documentation was comprehensive, but the process was arduous. Here is a small snippet of PHP for code that I wrote while implementing this feature.
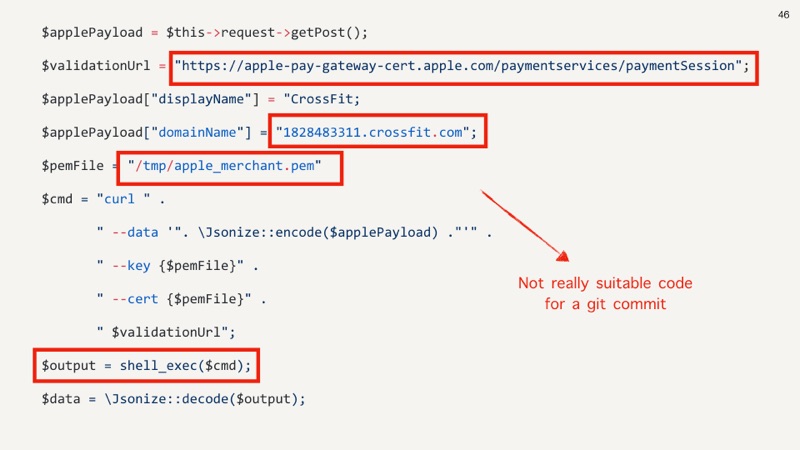
Look at all the hard coded-ness in there, absolutely awful, but necessarily as the code above is needed along side some JavaScript code, some configuration code within our Apple Pay account and within our payment gateway. The intent of this code was short lived and used to get the end-to-end to be demonstrably working as there are many moving parts.

And I totally committed this work. This work help demonstrate that the other, well-written, helper code actually worked as expected. Slowly but surely the code was re-worked into it's final production-ready state.

Refactoring is about small, behaviour preserving incremental and safe steps. Refactoring is not an excuse to go back and fix “TODOs” like what we saw with the Apple Pay example. There's a great quote from Kent Beck that I have repeated a few times already about making the hard change easy, and then making the easy change. My interpretation is that you want to refactor, rework, re-architect your system before trying to implement a change.
In a perfect world, you know exactly how to make the the hard change easy and prepare your code for the eventual change. In practice, that hard. Git rebase allows us to use near perfect hindsight so that your code changes flow as a coherent set of refactoring, and then the actual feature changes after.
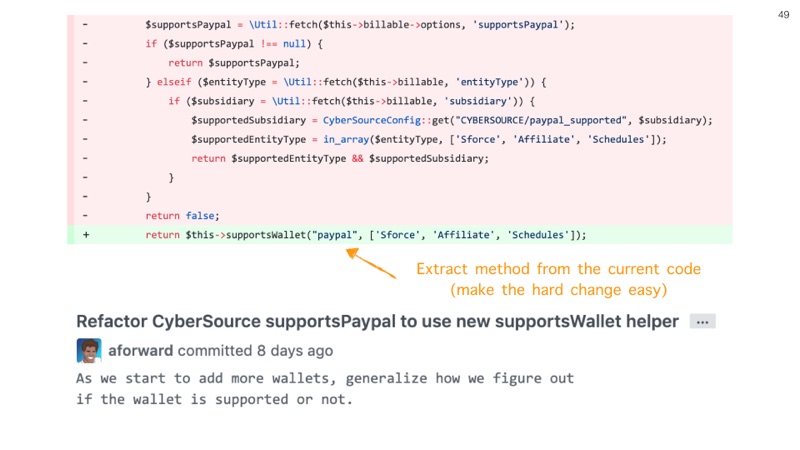
With our Apple Pay example, it became apparent, but not at first, to extract a PayPal method into a more generic wallet helper. This was originally discovered well after I had created duplicate code, but the final version had an isolated refactoring commit as you see above.
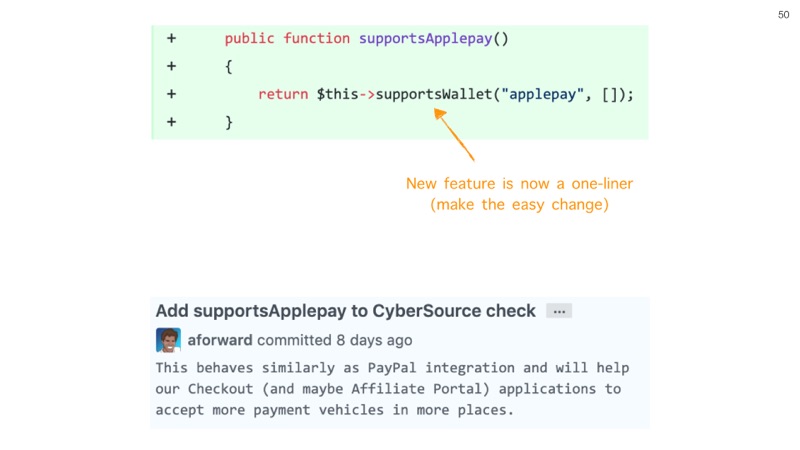
Adding support for ApplePay became a one-liner. This wasn't my first version of my solution, not even my second, but it was the solution that I delivered as a pull-request for review from my team. What an "easy change", I made :-)

Ideally our code is bug free. Second to ideally, we fix bugs in isolation. In reality, many times we fix bugs as we find them. By isolating bug fixes to just address the fixing of the bug we can then move those unrelated changes to the top of our branch commits. This gives us two benefits.
First, we don't have the overhead of fixing the bug in isolation if it's not needed.
But second, like we saw with Amy, we can easily cherry-pick that commit into a separately branch without being forced to prematurely pull in other code that isn't ready for production.

Here's a javascript bug that was observed when implementing apple way. Captured as as an isolated commit.

Separately, we had another bug fix for a syntax error in an exceptional scenario.

We could use this rev-list command to figure out how far back to go with our interactive rebase.
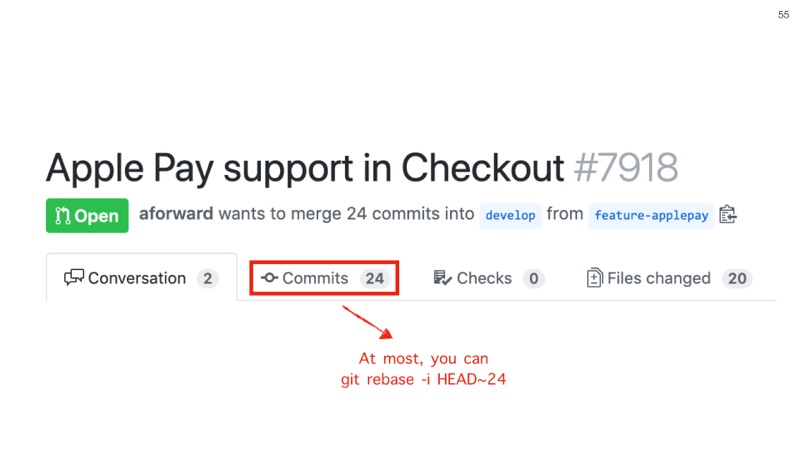
Or, I usually just use GitHub.

With interactive rebase, I locate those two unrelated bug-fix commits.
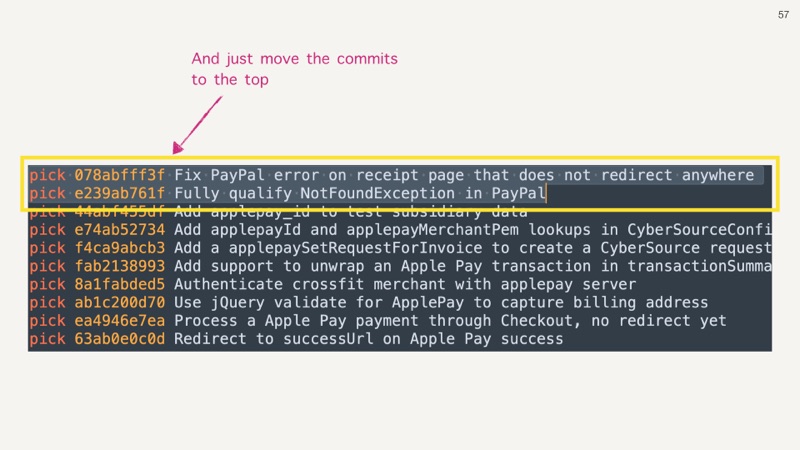
And move them to the top of the file. Now I am ready to cherry-pick, if needed, otherwise the bug fixes will go out when the overall feature is ready.
Pull request and git commit logs act as a great history of the evolution of your system. Consider organizing your commits by first addressing bugs, if any, then addressing refactoring, if any, and then providing feature tell a compelling story about how you made the hard change easy, and then how you made the easy change. It will tell a great story to those reviewing your code in more detail; it acts as great documentation about the "why" without riddling your code with comments; and it allows you the agility to split work out into separate pull-requests should some of your work be ok to merge, but others, not so much.
Git rebase gives us the tooling to alter our disorganized history into that coherent story allowing us to edit commit messages, re-order commits, fix up blemishes, squash commits into more logical grouping and easily pull in code from others.
Your future self, and other future maintainers will be thankful for the effort, in a similar manner that I hope you are thankful for the effort of speakers today trying to distill complex subjects down into 25 minute sound bites.